note、2025年8月からAI事業者にデータ提供 初期設定を確認
杉本崇
(最終更新:)
 noteのAI学習へのデータ提供プログラム
noteのAI学習へのデータ提供プログラム
メディアプラットフォームのnoteは2025年8月1日から、コンテンツがAI学習に利用された際に、その対価として得られた収益を還元するという「AI学習へのデータ提供プログラム」を本格的に始めます。noteは中小企業も活用していることが多いサービスです。プログラムの初期設定が「AI学習へのデータ提供プログラムに参加する」となっているため、自社の考え方に合わせて設定を確認しましょう。
noteとは
noteによると、noteは、クリエイターが文章や画像、音声、動画を投稿して、ユーザーがそのコンテンツを楽しんで応援できるメディアプラットフォームです。自社ブログをnoteで公表している中小企業や経営層も少なくありません。
2025年1月には、Googleと資本業務提携を発表し、AI技術を活用した新たなサービス開発を進める姿勢を明らかにしていました。投稿数は、2025年3月末時点で、5598万件と、この1年間で1100万件以上の記事が集まったといいます。
noteの「AI学習へのデータ提供プログラム」とは
noteは、2025年2月から3回にわたってAI学習によってクリエイターに対価が還元される実証実験を実施してきました。
その背景として「生成AIは私たちの創作活動を大きく後押ししてくれる一方で、学習データの許諾やクリエイターへの対価の仕組みは、まだ十分に整備されていません。また、インターネット上の作品がすでにAIに学習されている現状を完全に防ぐことは難しいという課題もあります」と説明しています。
実証実験の結果を踏まえ、noteは2025年8月から「AI学習へのデータ提供プログラム」を本格的に開始することにしました。
AI学習へのデータ提供プログラムの対象と設定方法
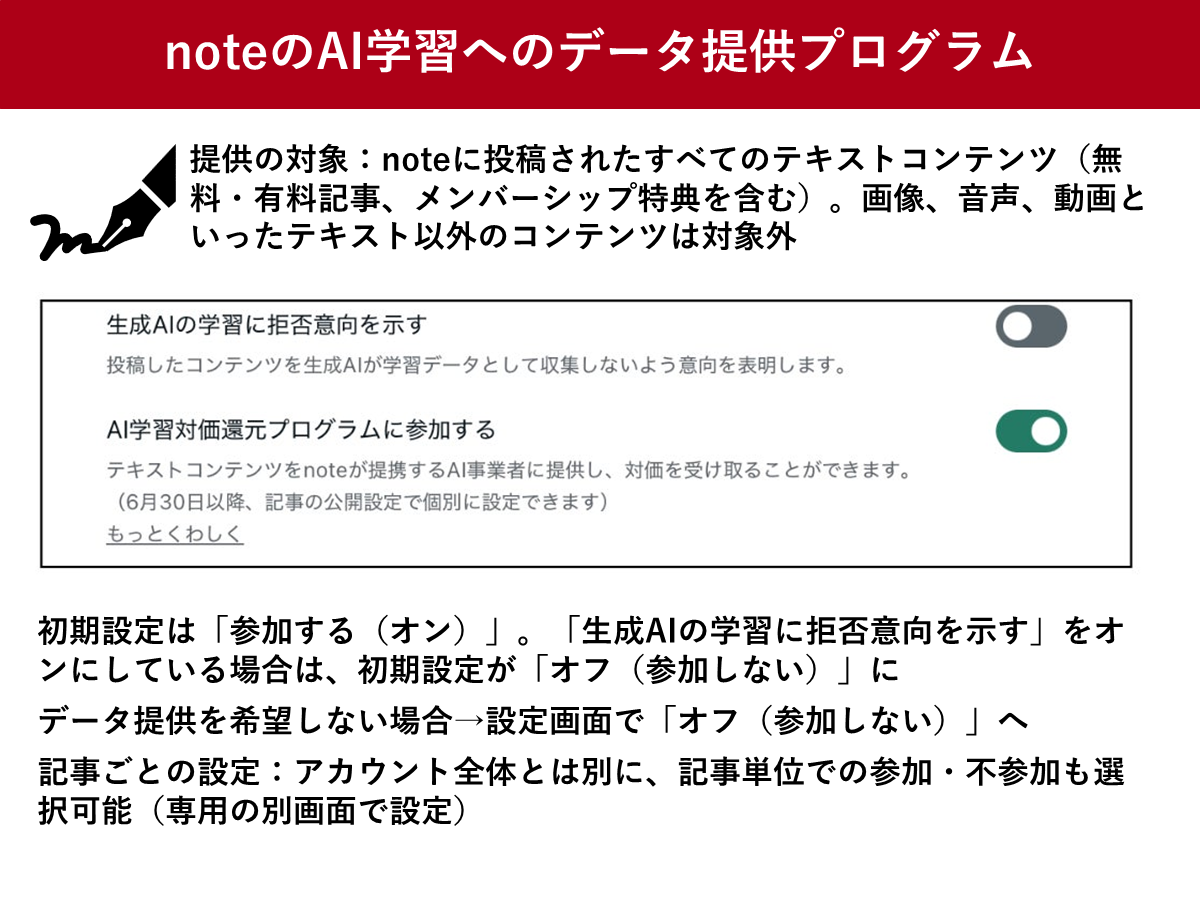
提供の対象となるのは、noteに投稿されたすべてのテキストコンテンツ(無料・有料記事、メンバーシップ特典を含む)です。画像、音声、動画といったテキスト以外のコンテンツは対象外となります。
コンテンツをAI学習に提供するか、対価を受け取るかについては、クリエイター自身が選択できますが、初期設定が「参加する(オン)」となっていることに注意が必要です。もしAI学習へのデータ提供を希望しない場合は、設定を変更して「参加しない」を選択してください。
プログラムに参加するメリット・デメリット
それでは、中小企業や経営層がこの「AI学習へのデータ提供プログラム」に参加するメリット・デメリットを考えてみました。
還元金をメリットとして考えるか
noteは「AI事業者から得た収益は、noteの運営手数料を差し引いたうえで、クリエイターのみなさんに分配いたします」と説明しています。収益源となるのは、メリットだとは言えるかもしれません。還元対象となる記事や還元額の基準は、記事のPV数・スキ数・文字数、文章の構成や表現、専門性などを元に、AIの学習データとしての有用性をnote側が総合的に評価して決定しますが、より詳しい評価基準は非公表です。
1回目の実証実験では、1200人以上が参加し、総額500万円超を還元し、一人あたりの最高額は40万円だったといいます。
ただし、コンテンツ制作を生業としている中小企業は限られているので、収益は限定的なものとなるかもしれません。また、企業としてnoteを利用している場合など還元金を受け取りたくない場合について「還元が発生し、対象となるクリエイターのみなさんへ個別にご連絡を差し上げる際に、還元の受け取り意思を確認させていただく予定です。その際、専用のフォーム等を通じて、還元金の受け取りを希望しない旨をご選択いただけるように準備を進めております」と回答しています。
LLMOの観点からの自社ブランド貢献
生成AIが普及するなかで、生成AIに使われている大規模言語モデル(LLM)の回答の引用元に自社のコンテンツが選ばれることを目的に最適化する「LLMO」という考え方が生まれています。
自社ブランドのために書いたnote記事が、AI学習に利用されることで自社ブランドにどのように貢献するのかは、まだよくわかっていませんが、よほど専門性の高いコンテンツでない限り。自社ブランドへの貢献は難しいでしょう。
noteは提供したコンテンツがどのように使われるかについて「現時点では、主に、言語モデルの思考力や言い回し、会話品質の向上などAI製品の品質向上を目的とした強化学習に活用される予定です。特定作品・作家の模倣、コピーを目的としたものではありません」と説明しています。
また、「自分の記事がAI学習にどの程度活用されたのか、貢献度などを後から知ることはできますか?」という質問に対しても、noteは「現在の仕組みでは、個別の記事がAI学習にどの程度活用されたかといった詳細なレポートを提供する機能はございません」と回答しています。
個人情報等のリスクは?
すでに公表しているnoteの文章に、個人情報が含まれている場合があります。
これについては「noteからAI事業者へデータを提供する前には、システムおよび人の目によって、記事本文やその他の公開コンテンツに含まれうる個人情報(例:クリエイターご自身が記事中に記載した氏名、住所、電話番号、メールアドレスなど)を可能な範囲で検知し、除外またはマスキング処理を施します」と説明しています。
経営者に役立つメルマガを配信 無料会員登録はこちら
この記事を書いた人
-
杉本崇
ツギノジダイ編集長
1980年、大阪府東大阪市生まれ。2004年朝日新聞社に記者として入社。医療や災害、科学技術・AI、環境分野、エネルギーを中心に取材。町工場の工場長を父に持ち、ライフワークとして数々の中小企業も取材を続けてきた。
杉本崇の記事を読む



